本文最后更新于 325 天前,其中的信息可能已经有所发展或是发生改变。
前言:自从ChatAI类产品大爆发至今已有个把年头了,但说实话真正下探到普通用户,作为一个可用好使的工具才刚刚起步,究其原因,我认为还是厂商们自己设的门槛都太高了,一方面是收费劝退了大量习惯免费工具的用户,另一方面则是作为迭代如此迅速的产品,各家却要将模型与自己的产品强行绑定,今天A领先明天B领先,谁也不想用落后的产品吧,而用户的迁移成本也是很高的,尤其是模型支持建立知识库以后。个人认为最好的路子是有专门的一类公司做安心做终端产品,去适配接入各家的模型并拓展丰富的应用场景,做模型的就专注模型多样化特长。但对于万恶的资本家来说估计不可能,所以就目前来说,只有开源的这些产品才能解决用户痛点:模型随时可以换,但是工具一定要稳定,私人数据一定要安全。那就让我们愉快的开始白嫖吧!
项目对比
ChatGPT-Next-Web
优点:有跨平台客户端,部署方便,预设众多
缺点:功能简陋,数据仅存本地无法多端同步
lobe-chat
优点:UI美观,支持多种身份认证和部署方式,插件市场丰富
缺点:数据库版本部署相当复杂,还要加上其它开源认证项目的部署详学习成本,对话反应太慢(猜测是判断是否调用插件这步导致),知识库必须使用支持向量的模型
open-webui
优点:极简界面非常舒服直观,配置简单但拓展能力MAX,目前功能已经非常完善,内置了文件解析、知识库搜索和语音对话
缺点:插件和预设安装比较麻烦,需要跳转至官方插件列表再导入
总之已经是我日常工作中高频使用的AI工具,所以接下来就重点介绍该项目的部署。
open-webui部署
docker容器配置
services:
open-webui:
image: ghcr.io/open-webui/open-webui
container_name: open-webui
restart: unless-stopped
volumes:
- /data/docker/ai/open-webui:/app/backend/data #指定数据保存目录
ports:
- 13000:8080
environment:
- TZ=Asia/Shanghai
- 'OLLAMA_BASE_URL=http://ollama:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
ollama: #可选,如果本地机器配置够好,可以尝试在本地跑一些开源大模型比如文生图这类
image: ollama/ollama
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- /data/docker/ai/ollama:/root/.ollama
environment:
- TZ=Asia/Shanghai
mzzsfy-tts: #大佬封装的微软语音转文本接口https://github.com/mzzsfy/Dockerfile
image: mzzsfy/tts
container_name: mzzsfy-tts
restart: unless-stopped
ports:
- 14000:8080
environment:
- TZ=Asia/Shanghai
- WEB_KEYWORD_WHITELIST=中文
tika: #apach开源文件内容提取,用于知识库内容识别
image: apache/tika:latest-full
container_name: tika
restart: unless-stopped
ports:
- "13998:9998"
environment:
- TZ=Asia/Shanghai
user: "0:0"
healthcheck:
#安装中文orc
test: sh -c "if [ ! -f health ]; then apt update && apt install -y tesseract-ocr-chi-sim && touch health ; else exit 0; fi"
start_period: 1s
kimi-free-api: #kimi逆向工程封装的白嫖代理https://github.com/LLM-Red-Team/kimi-free-api
container_name: kimi-free-api
image: vinlic/kimi-free-api:latest
restart: unless-stopped
ports:
- "18000:8000"
environment:
- TZ=Asia/Shanghai
qwen-free-api: #阿里通义千问白嫖代理https://github.com/LLM-Red-Team/qwen-free-api
container_name: qwen-free-api
image: vinlic/qwen-free-api:latest
restart: unless-stopped
environment:
- TZ=Asia/Shanghai应用配置
-
禁用新用户登录
因为openwebui用户鉴权这块做得比较简单(其实非常适合个人或家庭使用),可以自助注册登录,所以我们首次访问创建好管理员账号后直接禁用新用户注册,或者注册为待激活状态,这样就很安全

-
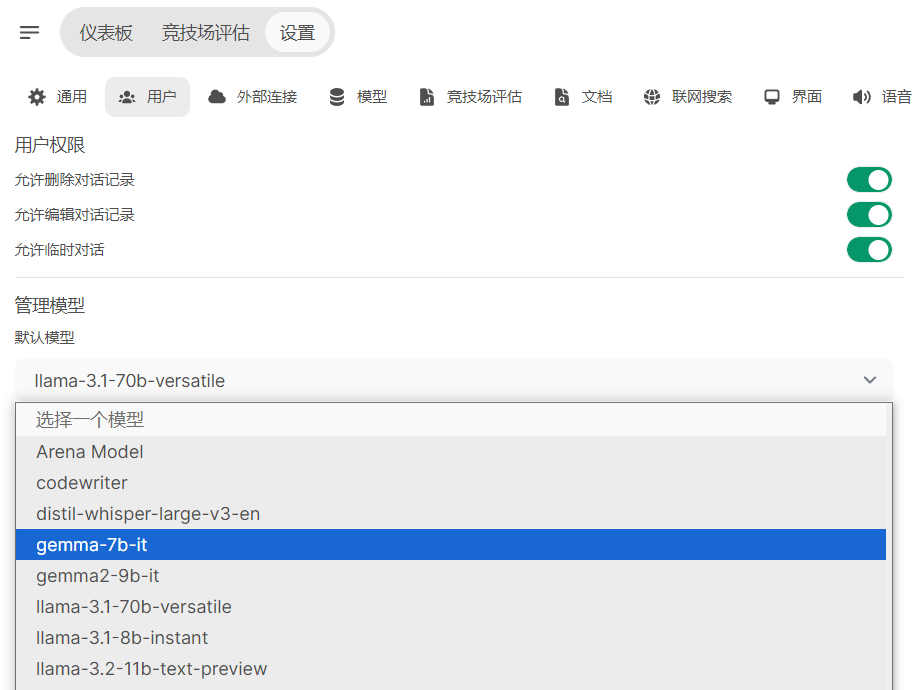
配置白嫖AI对话模型接口
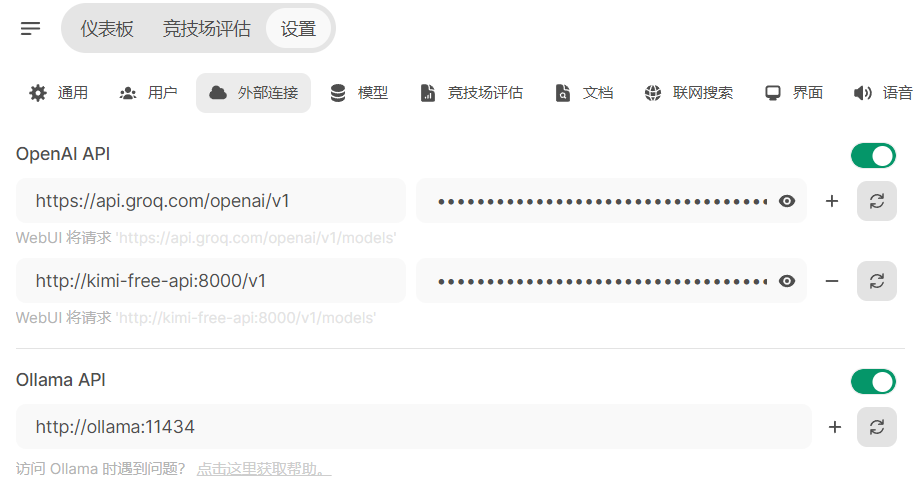
这里我推荐两个免费接口:Groq和Kimi
Groq 模型比较小,但胜在免费稳定,响应超快,关键还有whisper模型可以识别语音,不过需要魔法上网(普通机场不行,需要能访问OpenAI那种,推荐使用cf的WARP二次代理)
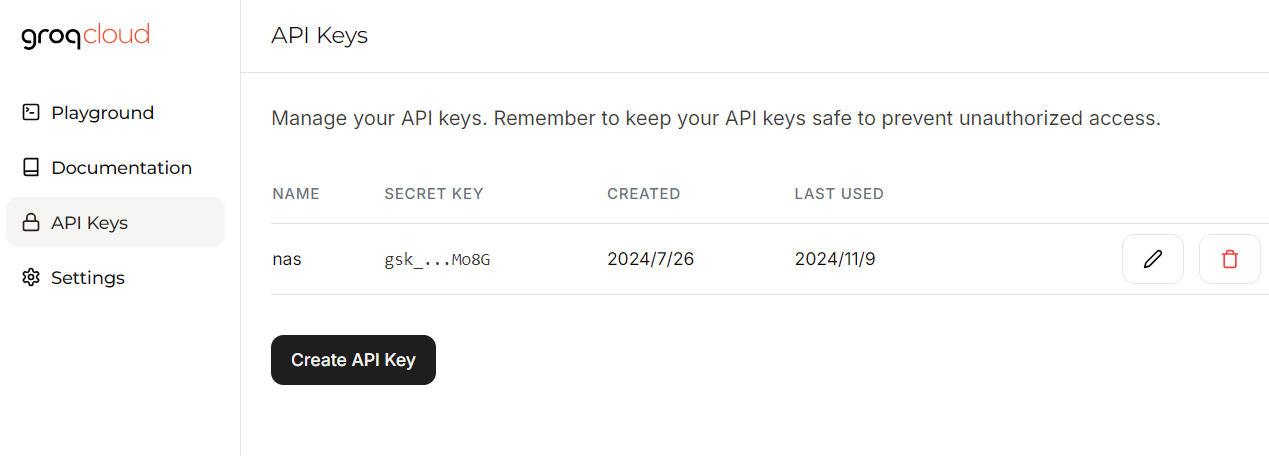
- 注册 https://console.groq.com
- 创建API key
- 配置到Openwebui(https://api.groq.com/openai/v1)
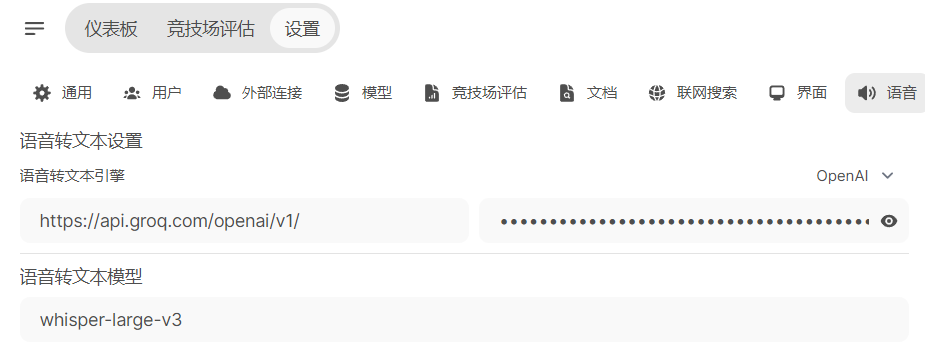
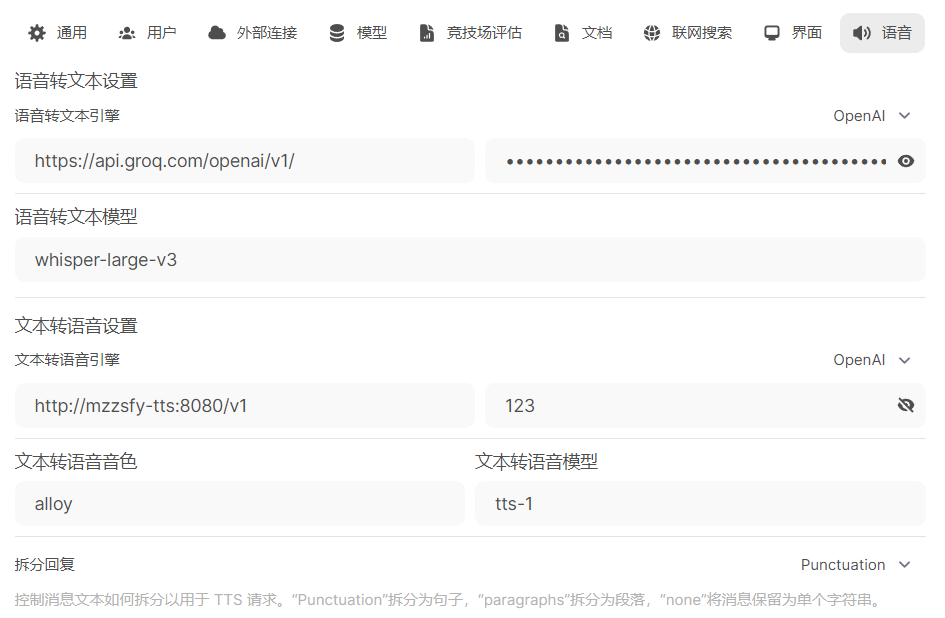
- 语音识别配置
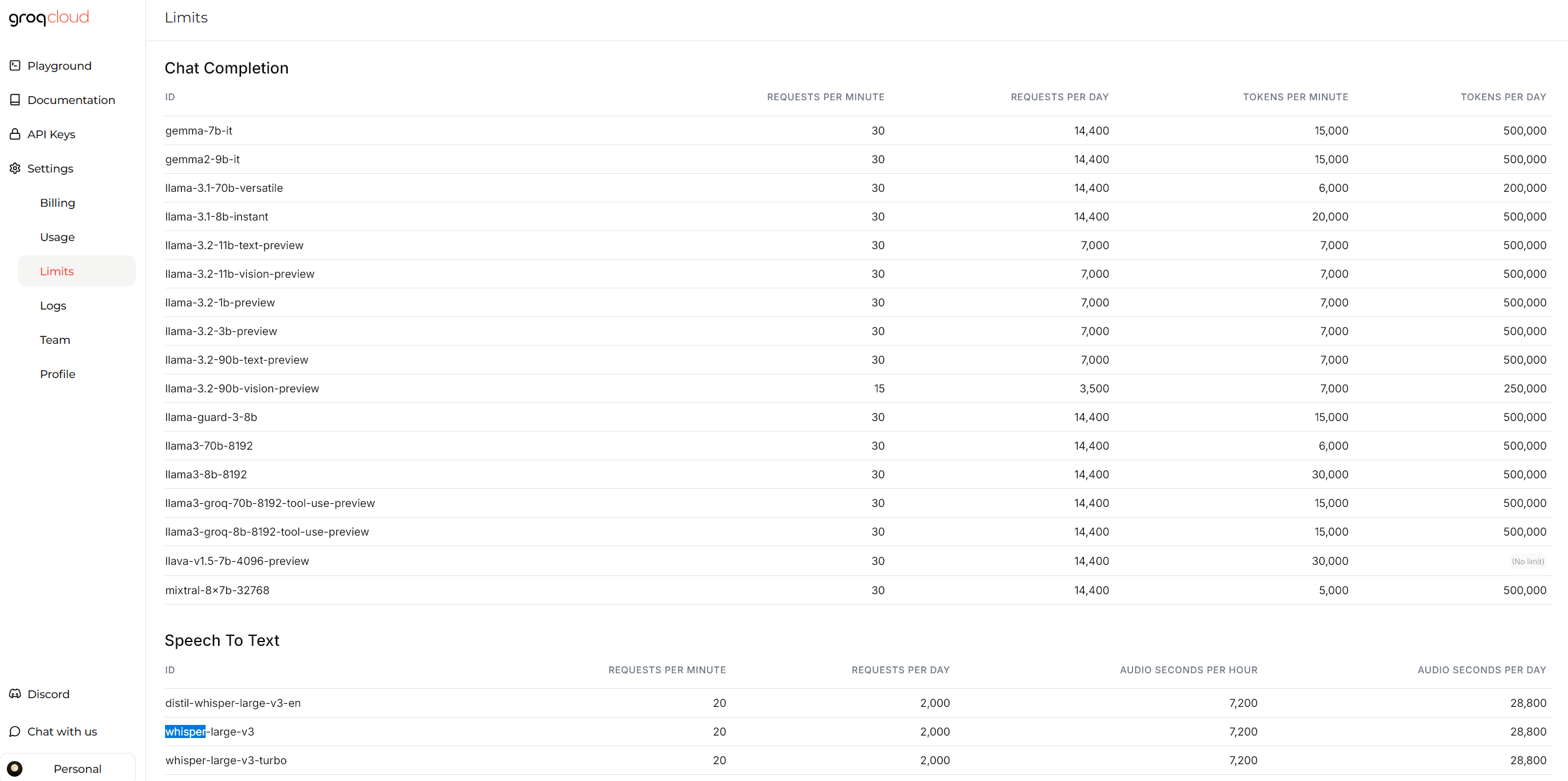
- 注意每日限额,普通对话非大本文一般够用
Kimi 支持超长上下文、图片识别、联网搜索,逆向API不稳定且用且珍惜
- 访问确认刚部署的Kimi代理服务(kimi-free-api)正常:http://你的本地ip:18000
- 注册登录Kimi https://kimi.moonshot.cn
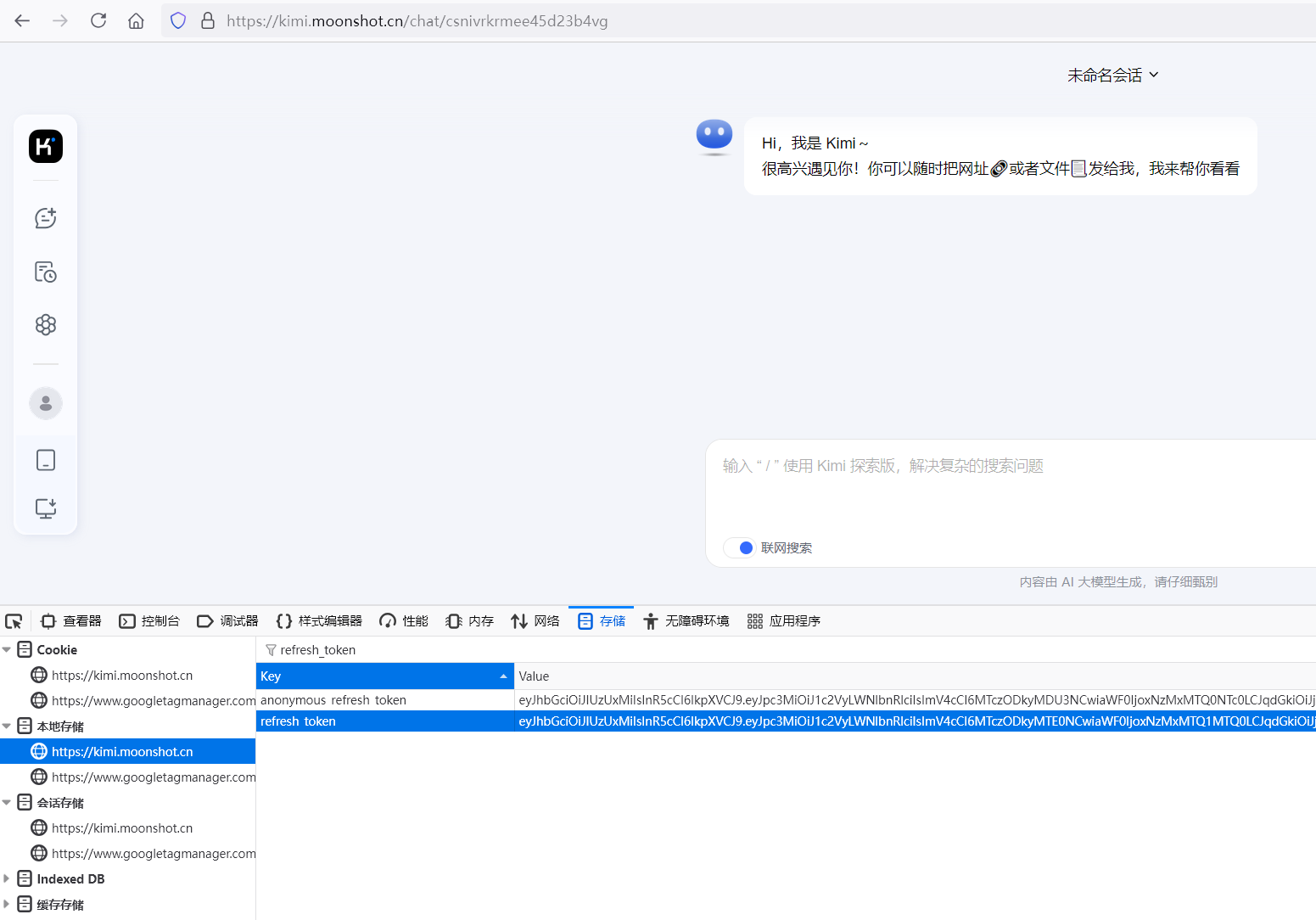
- 随便对话后F12打开浏览器控制台,在存储-本地存储中找到refresh_token
- 配置到openwebui(http://kimi-free-api:8000/v1)
- 默认模型配置,选一个你喜欢的groq或者kimi的模型
-
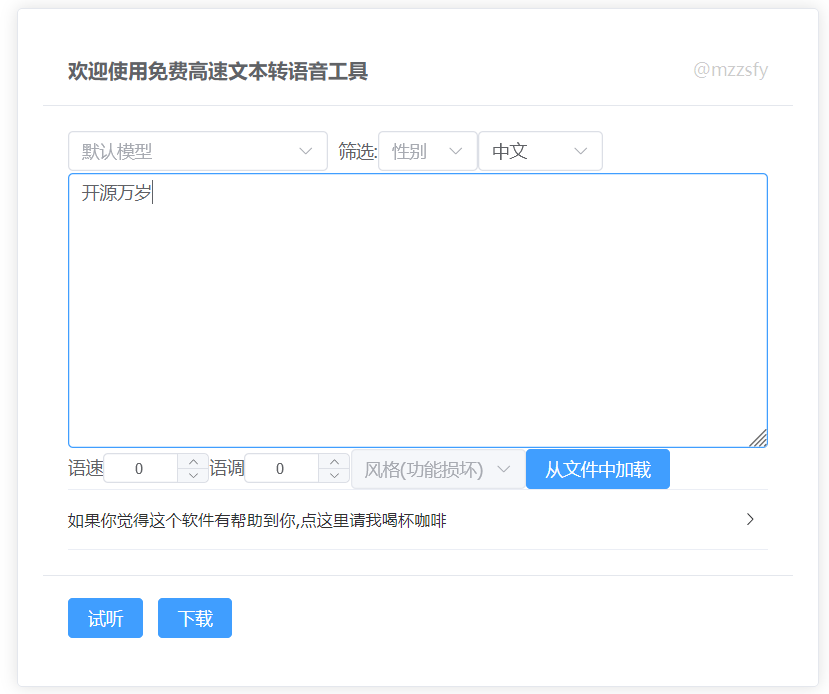
文本转语音配置
- 访问刚部署的mzzsfy-tts应用,试听确认正常即可:http://你的本地ip:14000
- 配置到openwebui,key随便填,如果要调整音色可使用azure文档中不带小标的音色名称
- 访问刚部署的mzzsfy-tts应用,试听确认正常即可:http://你的本地ip:14000

OpenWebUI 功能概览
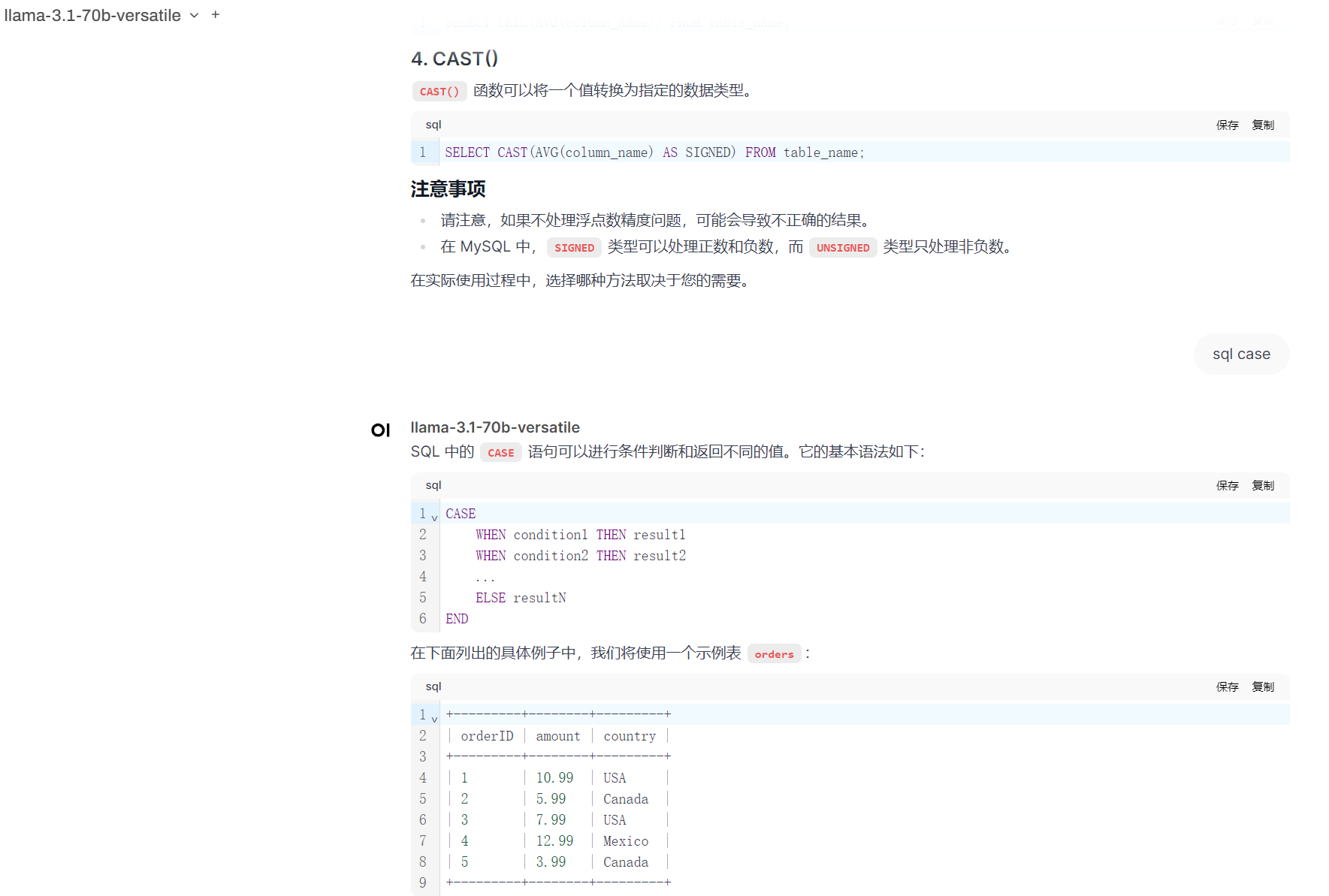
日常编码辅助
图片识别(kimi)
联网搜索总结
知识库对话
部署介绍就先到这,大家快去探索一下吧


大佬什么时候出个博客教程.